이전 정리글까지는 network layer의 data plane, forwarding 방식이 어떻게 이루어지는지, 그리고 그 forwarding이 일어나는 router의 구조는 어떻게 되어있고, 어떤 action을 하는지 등에 대해서 정리해 보았다.
이번 정리글부터는 routing을 담당하는 Netowkr Layer의 control plane에 대해서 정리해 보려고 한다.
1. Control Plane
앞서, 네트워크 계층은 data plane과 control plane으로 나뉜다고 정리했고, 이전 정리글까지는 data plane에 대해서 정리해 보았다. 네트워크 계층의 기능에 대해서 다시 정리해 보면,
- forwarding : 패킷을 라우터의 input 포트로부터 적절한 output 포트로 옮기는 것 > data plane
- routing : source에서 destination까지 패킷을 전달할 때 경로를 정하는 것 > control plane
이때, network control plane을 구성할 때, 두 가지 접근법이 있다.
- per-router control(전통적인 방식)
- logically centralized control(소프트웨어 기반 네트워킹=SDN(Software-Defined Networking))
먼저, per-router control 방식에 대해서 알아보자.
1.1 Per-router Control Plane
이 방식은 각각의 router에서 자체적으로 routing algorithm을 실행시켜, control plane에서 서로 그 결과값을 공유하여 routing 경로를 결정하고 forwarding table을 작성하는 방식이다. 즉, 각 라우터는 Control Plane과 Data Plane을 모두 내장하고 있으며,라우터 내부에서 이 둘이 직접 상호작용하게 된다. 다음 그림을 참고하자.

위 그림을 예로 들어, 0111헤더가 붙은 패킷이 전달되려고 할 때, 각 라우터에서 라우팅 알고리즘을 계산해 그 결과값을 서로 공유하고, 공유한 결과를 바탕으로 각 라우터의 forwarding table을 작성하는 방식이다.
이 방식은 인터넷 초창기부터 사용된 전통적인 방식으로, 라우터의 개별 분산 판단 능력에 의존한다는 특징이 있다.
1.2 SDN(Software-Defined Networking)
이 방식은 1.1의 방식과 달리, 각 router에서 routing algorithm을 적용시키는 것이 아니라, 중앙의 원격 controller가 존재해 라우팅 결정을 대신 수행한다. 즉, controller가 전체 네트워크의 라우팅 정보를 중앙에서 수집하고 분석한다. 그 후, 라우터에 forwarding table을 install해주는 방식이다. 다음 그림을 살펴보자.
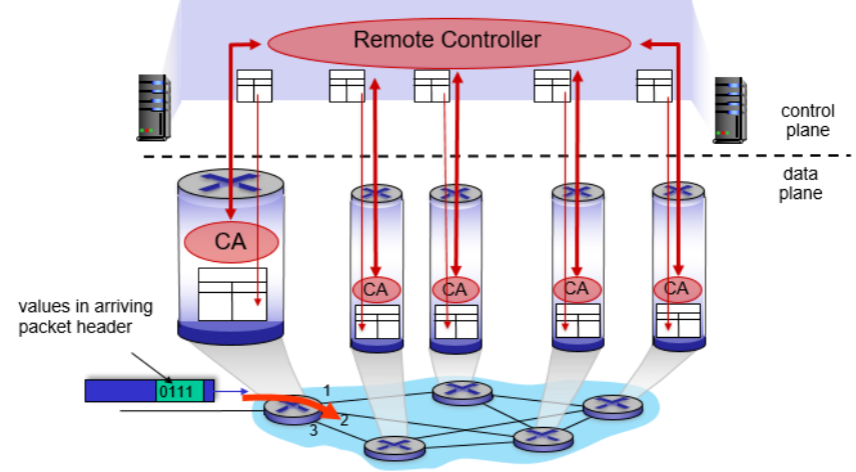
그림을 보면 알 수 있듯이, 1.1의 방식과 달리 라우터 라우터 내에 control plane이 존재하지 않고, 원격의 controller가 CA(Control Agent)를 통해 라우터와 정보를 주고 받으며, routing algorithm을 계산한 뒤, forwarding table을 만들어 라우터에 전달해준다.
2. Routing Protocols
그럼 이 routing을 해주는 프로토콜에는 무엇이 있을까? 먼저, routing protocol의 goal을 알아보자.
Routing protocol goal:
determine "good" paths(=routes), from sending hosts to receiving host,
through network of routers
즉, 좋은 라우터 경로를 찾는 것이다. 이때, path와 good은 다음을 의미한다.
- path : 주어진 source host로부터 final destination host까지 패킷이 이동하는 라우터의 순서
- good : least cost, fastest, least congested
이런 라우팅 프로토콜은 top-10 networking challenge에 속한만큼, 어렵고, 중요한 과제이다.
최적의 경로를 찾는 방법 중 가장 좋은 것은 graph로 나타낸 뒤 계산하는 것이다. 다음 그림을 한 번 살펴보자.
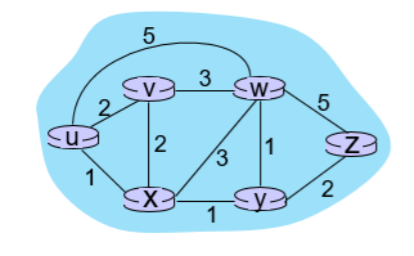
위 그림과 같이, router와 link들을 weighted graph로 나타낸 것이다. 이때, 이 graph를 G라고 하면 G는 다음과 같이 나타낼 수 있다.
G = (N,E)
그라프는 보통 (Vertex, Edeges)로 나타낸다. 이때, N과 E는 각각 다음을 의미한다.
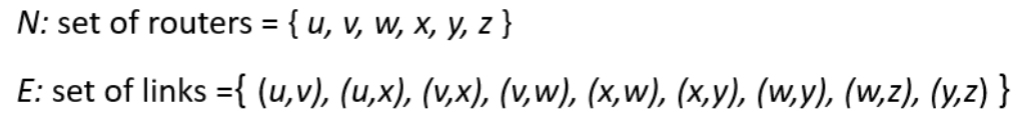
그리고 이때, 다음c를 다음과 같이 정의한다.

즉, a와 b 사이에 직접 연결된 link가 있다면, 그 link의 가중치 값이 c가 되고 아니면, 무한대로 표시한다. 예를 들어, c(w,z) = 5 로 나타낼 수 있고, c(u,z) = 무한대로 나타낼 수 있다.
참고로, 이런 link들의 가중치는 네트워크 운영자에 의해 정의될 수 있다.(모두 1이 될 수도, 아니면 bandwidth나 혼잡도에 따라 다르게 나타낼 수도)
그리고, 위의 그라프는 간단하게 나타낸 것인데, 사실 link는 양방향성이 있기 때문에 directed graph로 나타내야 정확하다.
3. Routing Algorithm Classification
라우팅 알고리즘은 다음과 같이 분류할 수 있다.

먼저, 그림의 세로축은 다음과 같이 구분한다.
- global : 모든 라우터들이 완벽히 동일한 link cost 정보를 알고 있을 때, global하다고 한다. "link state" 알고리즘이 이에 해당한다.
- decentralized : 각자 link cost를 계산한 뒤, 이웃들끼리만 정보를 교환하는 것. "distance vector" 알고리즘이 이에 해당한다.
decentralized에 대한 예를 더 자세히 들어보면, 서울에서 부산까지 가는 상황에서 서울은 수원/구리와 같은 이웃 도시들과 연결 상태만 알고 있고, 이들로부터 간접적으로 정보를 받아 최적 경로를 점진적으로 계산하는 것이다.
- 서울에서 수원: 1시간 30분
- 서울에서 구리: 2시간
- 수원/구리에서 대구 : 2시간
- 대구에서 부산 : 2시간
위 정보를 통해 서울은 수원-대구-부산이 최적 경로임을 재귀적으로 알아내는 방식이다. 뒤에서 더 자세히 설명할 예정이니 참고로만 알아두자.
다음으로, 그림의 가로축은 다음과 같이 구분한다.
- static : 정해진 경로에서 거의 바뀌지 않는다.
- dynamic : 경로를 동적으로 바뀐다. (원래 가려고 했던 link의 혼잡도가 증가하면, 다른 경로로 바꾼다.)
'학교공부 > [컴퓨터 네트워크]' 카테고리의 다른 글
| [컴퓨터 네트워크] - Netowrk Layer_Distance vector (1) | 2025.06.07 |
|---|---|
| [컴퓨터 네트워크] - Network Layer_link-state (0) | 2025.06.07 |
| [컴퓨터 네트워크] - Network Layer_Middleboxes (0) | 2025.06.06 |
| [컴퓨터 네트워크] - Network Layer_Generalized Forwarding (0) | 2025.06.06 |
| [컴퓨터 네트워크] - Network Layer_IPv6 (0) | 2025.06.05 |



